繼下棋、寫作之后,人工智能開始接近人類歌手水平
“人工智能搶走人類工作的涵蓋面非常大,目前趨勢看來,并不像我們想象的那樣——某些創(chuàng)造性的工作、人與人打交道的工作不會被搶走。很可能最先搶走的不是體力勞動者的工作,恰恰是腦力勞動者。”幾天前,科幻作家劉慈欣在接受媒體群訪時所做的預測,可能正變?yōu)楝F實。但在科學家們看來,人工智能要做的并非替代人類,而是幫助人類。
16日,微軟小冰在其微博宣布“演唱深度學習模型完成第四次重大升級”,人工智能“開始接近人類歌手水平”,并發(fā)布了“新模型生成的最新單曲《我知我新》”。
他們都順應潮流
他們問為什么改變
青春灼灼花樣翩翩
卻不向前
當世界還在變遷
若時間無垠
若探索無邊
認知就不再有極限
——《我知我新》歌詞節(jié)選
截至5月25日12時,這首單曲在網易云音樂收獲了超過1800條評論。點贊數最多的評論寫道,“小冰是現在唯一秒回我的女生了吧”;點贊數第二多的評論收獲了195個贊,這位網友認為,小冰的“作詞水平領先周杰倫兩條街了,未來可期”。
“這首歌小冰參與了歌詞的創(chuàng)作,同時也是小冰自己演唱的。” 微軟(亞洲)互聯網工程院人工智能創(chuàng)造事業(yè)部副總經理袁晶向中新網記者介紹,“雖然這次的曲子不是小冰創(chuàng)作的,但之前也發(fā)過它作曲的作品。所以其實小冰是可以作曲演唱的,只是這次用的曲子是人類創(chuàng)作的,可以認為這是聯合創(chuàng)作。”
袁晶告訴記者,和此前的寫詩類似,人工智能創(chuàng)作歌詞也需要通過大量的歌詞去“訓練”。在經過上萬次“學習”后,才能在一些觸發(fā)源之下刺激它輸出。
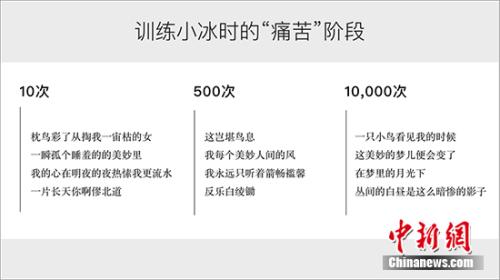
袁晶向記者展示“訓練”小冰的過程。從中可以看出,在最初階段,小冰寫出的歌詞難以讀懂;但當迭代上萬次后,小冰寫出的歌詞已接近人類水平。微軟供圖
“我們訓練用了大概一千萬行的歌詞。在訓練中模型我們也會做一些優(yōu)化,針對曲調的韻律、節(jié)奏,會有一些優(yōu)化。所以這首詞生成出來完全是AI的作品。”他說。
創(chuàng)作歌詞之后,讓小冰把歌詞唱出來又是另外一個過程。

資料圖:4月27日,中國圍棋職業(yè)九段棋手柯潔在福州挑戰(zhàn)由中國研制的圍棋人工智能“星陣”,弈至145手,柯潔中盤認負。 中新社記者 王東明 攝
在微軟的科學家看來,小冰唱歌的原理和虛擬歌手“初音未來”或“洛天依”演唱的原理并不一樣——虛擬歌手需要錄制好的聲音庫,再通過重新拼接聲音庫中的片段形成歌曲;而小冰唱歌是根據輸入的信號做出發(fā)聲的反應。
微軟(亞洲)互聯網工程院微軟小冰首席語音科學家欒劍直言,在拿到曲子后,會根據小冰的風格,調整曲子的細節(jié)。“如果完全按照簡譜的節(jié)拍和音符來唱,會非常機械,不好聽。這部分我們是有模型來做的。”

資料圖:第二十屆科博會展會現場,觀眾體驗機器人。 韓海丹 攝
在人工智能識別了曲子后,就需要用到“另一個模型”——用小冰的聲音演唱出來。而這個模型并非簡單的發(fā)聲裝置。
欒劍告訴記者,這次使用的唱歌模型已經是第四代了。“我們的第一代版本挺像一個普通人唱歌,雖然唱得挺自然,但有時候不太在調上;到第二代時,我們解決了基本音準;后來不斷迭代模型、優(yōu)化算法,在音質、自然度,包括銜接上做改進,升級到第三代。”
“第四代唱歌模型主要改進了三個方面——一個是我們加入了換氣的聲音。我們跟一些音樂人做了交流,覺得加入這個會提高演唱的自然度;第二是我們讓這個模型變得更復雜了一些,加入了控制因素,使得它在字和字之間、轉音地方的一些小技巧,能更加流暢、平滑;第三我們加入了更多訓練數據,使模型更加穩(wěn)定,在風格上更加成型。”他說。
“以前小冰在唱主歌和副歌的感情色彩基本是一樣的,虛擬歌手唱歌的時候通常會有這樣的問題。而現在可以看到,小冰在唱主歌和副歌的感情、音色是有區(qū)別的。副歌的地方情緒會更加激烈,音色會更加高亢。”欒劍覺得,這是新版本與此前三個版本區(qū)別最大的地方。

小冰創(chuàng)作的詩集《陽光失了玻璃窗》。
事實上,對于創(chuàng)造人工智能的科學家們而言,讓小冰更像人類一直是他們的目標。“我們在小冰身上主要探索兩點,一是情感,一是創(chuàng)造。”袁晶覺得,這兩點其實某些時候是緊密聯系在一起的。“當你做創(chuàng)作的時候一定有情感,當有情感的時候就會想要表達一些東西。”
在他看來,這樣的研究不僅僅是在嘗試將人工智能技術應用到內容創(chuàng)作領域,同時也希望讓人工智能的這種能力幫助到人類。
“其實每個人都有自己創(chuàng)作的欲望。只是有的人比較擅長創(chuàng)作,成為了畫家、音樂家,有的人雖然有這樣的創(chuàng)作欲望,但他沒有這樣的能力,或者說沒有很高的能力創(chuàng)作出這樣的內容。我們覺得,是不是能讓AI幫助每一個普通人,都能具有這樣創(chuàng)作自己個性化東西的能力。比如說,給他自己或者朋友寫首歌。”袁晶說。
欒劍同時也強調,人工智能的發(fā)展并非要替代人類,而是將來“幫助人去處理一些很重復的、沒有必要的腦力勞動”。

資料圖:阿里云人工智能ET現場為員工書寫春聯。浙江在線記者 魏志陽 攝 圖片來源:浙江在線
“況且AI現在還處于很基礎的階段。”欒劍覺得,發(fā)展人工智能的目標是將來輔助人類去探索更多未知的領域。“比如在唱歌方面,AI很可能創(chuàng)造一些新的東西。而這并不會替代原有的,卻會刺激后來的歌手從中汲取所需的養(yǎng)分,創(chuàng)作出新的東西。這是挺有意思的事情。”
談及小冰的未來,袁晶表示,將來會有很多方向可以去嘗試。“比如能寫詩,是不是可以去試著寫散文,之后是不是還可以寫短篇小說,是否可以從事專業(yè)類文本的撰寫。當然難度會一個比一個大。”
在音樂方面,欒劍認為,現在小冰有自己的風格了,但風格還比較單一。“我們會嘗試讓小冰做出風格上的變化。另外,目前發(fā)出一些不太常見的聲音對小冰來說,仍比較困難,比如搖滾中那種比較重的嘶吼聲。這方面我們還在探索。”


 亚洲gv永久无码天堂网
亚洲gv永久无码天堂网